OpenAI has officially unveiled two new open-source Artificial Intelligence models, making a significant move toward greater transparency and community collaboration. Announced on Tuesday, the models—named gpt-oss-120b and gpt-oss-20b—are available free of charge and are positioned as competitive alternatives to OpenAI’s proprietary o3 and o3-mini models.
This announcement represents OpenAI’s first major open-source contribution in nearly six years, following the public release of GPT-2 in 2019. According to the San Francisco–based AI company, both models are built on a mixture-of-experts (MoE) architecture and have undergone extensive training and safety evaluations. The open weights for both gpt-oss models are now publicly accessible and can be downloaded via OpenAI’s official Hugging Face repository.
Native Reasoning and Tool Use at the Core of OpenAI’s Open-Source Models
OpenAI CEO Sam Altman confirmed the release in a post on X (formerly Twitter), highlighting the performance capabilities of the larger model. “gpt-oss-120b performs about as well as o3 on challenging health-related issues,” Altman noted, signaling confidence in the model’s reasoning depth and real-world applicability.
Both gpt-oss-120b and gpt-oss-20b are hosted on OpenAI’s Hugging Face page, allowing developers, researchers, and enterprises to download and deploy the models locally. This local deployment capability is particularly valuable for organizations seeking greater control over data, infrastructure, and customization.
According to OpenAI’s official documentation, the new open-source models are compatible with agentic workflows and integrate seamlessly with the company’s Responses application programming interface (API). They also support advanced tool usage, including online search capabilities and Python code execution, making them suitable for complex, multi-step tasks.
A key highlight of these models is their transparent chain-of-thought (CoT) reasoning. This native reasoning capability allows users to observe and tune how the model arrives at its answers. Developers can adjust the models to prioritize either low-latency responses or higher-quality, more detailed outputs, depending on their specific use cases.
From an architectural standpoint, both models leverage the mixture-of-experts (MoE) approach to improve efficiency by activating only a subset of parameters for each token. The gpt-oss-20b model activates approximately 3.6 billion parameters per token, while the larger gpt-oss-120b activates around 5.1 billion parameters.
In terms of total parameters, gpt-oss-120b contains roughly 117 billion parameters, whereas gpt-oss-20b has around 21 billion. Despite this difference, both models support an impressive context window of up to 128,000 tokens, enabling them to handle long documents, extended conversations, and complex reasoning tasks.
Training data for these open-source AI models was predominantly English-language text, with a strong focus on general knowledge, software development, and STEM disciplines—science, technology, engineering, and mathematics. OpenAI emphasized that the models were designed to perform well across both analytical reasoning and practical coding scenarios.
During the post-training phase, OpenAI applied reinforcement learning (RL)–based fine-tuning to further refine model behavior, improve response accuracy, and enhance alignment with user intent.

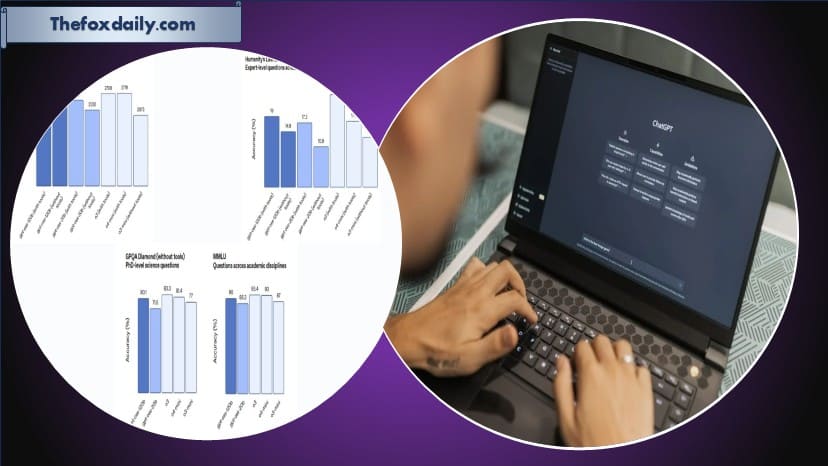
Benchmark performance of OpenAI’s open-source models (Image courtesy: OpenAI)
Based on internal benchmarking, OpenAI claims that gpt-oss-120b outperforms o3-mini in several important areas. These include tool calling efficiency measured by TauBench, general problem-solving benchmarks such as MMLU and Humanity’s Last Exam, and competitive programming performance on platforms like Codeforces.
However, the company also acknowledged that on certain high-level evaluation metrics—such as GPQA Diamond—the open-source models generally trail behind the proprietary o3 and o3-mini models. This transparency reflects OpenAI’s effort to clearly communicate both strengths and limitations.
Safety remains a central focus despite the open-source nature of the release. OpenAI stated that both models received extensive safety training during development. Harmful content related to chemical, biological, radiological, and nuclear (CBRN) risks was removed during the pre-training phase.
In addition, OpenAI implemented multiple safeguards to ensure that the models reliably reject dangerous prompts and are resilient against prompt injection attacks. These measures are intended to balance openness with responsible AI deployment.
Addressing concerns around misuse, OpenAI asserted that the gpt-oss models have been trained in a way that prevents malicious actors from easily fine-tuning them for harmful purposes, even though the weights are openly available.
With the release of gpt-oss-120b and gpt-oss-20b, OpenAI has taken a notable step toward open AI development, offering powerful reasoning models to the broader community while maintaining a strong emphasis on safety, performance, and transparency.
For breaking news and live news updates, like us on Facebook or follow us on Twitter and Instagram. Read more on Latest Technology on thefoxdaily.com.





COMMENTS 0